

타이타닉 생존율 예측
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snspath=r'./train_final.csv'
train_final = pd.read_csv(path)
path=r'./test_final.csv'
test_final = pd.read_csv(path)train_final.columns
feature_names = ['Age_s', 'Fare_s',
'Pclass_2', 'Pclass_3', 'Sex_male', 'Embarked_Q', 'Embarked_S',
'Name_c_Master', 'Name_c_Mr', 'Name_c_Woman', 'Family_c_Big_f',
'Family_c_Small_f']# feature => 2차원
# target => 1차원
X = train_final[feature_names]
y = train_final['Survived']# train / test 셋 분리
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y,
test_size=0.3,
random_state=1,
stratify=y)
# stratify : 훈련, 테스트의 카테고리 비율을 동일하게 맞춤KNN
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
# KNN 모델의 하이퍼 파라미터 찾기
score_list = []
for k in range(1,51):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score( knn, train_x, train_y, cv=5 ).mean()
score_list.append(score)plt.figure(figsize=(5,3))
plt.plot(range(1,51), score_list)
plt.show()
# k=13으로 찾음!
# knn 모델 생성
knn = KNeighborsClassifier(n_neighbors=13)
# 훈련
knn.fit(train_x, train_y)
# 검증
knn.score(valid_x, valid_y)
# test 데이터를 예측!
knn_result = pd.DataFrame( test_final['PassengerId'] )
knn_result['Survived'] = knn.predict( test_final[feature_names] )
knn_result.to_csv( r'knn_result.csv', index=False )SVM(서포트 벡터 머신)
- 하이퍼 파라미터 C : 경계선 부근에서 틀리는 것에 대한 비용
- 너무 높으면 아웃라이어도 틀리는 것을 허용못하고 포함 => 오버피팅
- 너무 낮추면 전체 데이터 맥락도 다 틀려버림 => 언더피팅
- gamma : 고차원에서 데이터에 얼마나 핏한 평면을 만들 것인가
- 너무 높으면 오버피팅
- 너무 낮으면 언더피팅
그리드서치(gridsearch)
- 사이킷런에서 하이퍼파라미터가 여러개일 경우, for문 없이 최적의 파라미터를 찾을 수 있도록 지원
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
params = {'C':[0.01, 0.1, 1, 10],
'gamma':[0.01, 0.1, 1, 10]}
# 1. grid 모델 생성
grid_svm = GridSearchCV( SVC(), params, cv=5 )
# 2. grid 모델 훈련
grid_svm.fit(train_x, train_y)# 최적의 파라미터 확인
grid_svm.best_params_
# {'C': 1, 'gamma': 0.1} 출력# 피벗테이블로 확인
cv_result_svm = pd.DataFrame( grid_svm.cv_results_['params'] )
cv_result_svm['score'] = grid_svm.cv_results_['mean_test_score']
pd.pivot_table( cv_result_svm,
index='C',
columns='gamma',
values='score',
aggfunc='mean')# 검증
grid_svm.score( valid_x, valid_y )
# 예측
grid_svm.predict( test_final[feature_names] )svm_result = pd.DataFrame( test_final['PassengerId'] )
svm_result['Survived'] = grid_svm.predict( test_final[feature_names] )svm_result.to_csv('./svm_result.csv', index=False)Tree 모델
- gini 계수
- 분류의 경우, Tree 모델을 많이 사용
- 해석력이 뛰어남
- 다른 모델은 blackbox로 모델에 영향을 주는 feature를 구분하기 힘들지만, Tree 모델의 경우, feature selection에 용이
- 수행이 쉬움
- gini 계수
- 데이터가 얼마나 순수한지
- Max_depth
- 1의 경우 제한 없이 트리 구분을 끝까지 진행 --> 오버피팅 우려
- Tree를 몇개까지 남기고 구분을 해야하는지 지정해야하는 하이퍼 파라미터
from sklearn.tree import DecisionTreeClassifier, plot_tree
params={'max_depth':[3,5,10,30],
'min_samples_leaf':[1,10,30,50]}
grid_tree = GridSearchCV( DecisionTreeClassifier(), params, cv=5 )
grid_tree.fit(train_x, train_y)# 최적의 파라미터 값
grid_tree.best_params_
# {'max_depth': 5, 'min_samples_leaf': 1} 출력# 종합적인 보고서
cv_result_tree = pd.DataFrame( grid_tree.cv_result_['params'] )
cv_result_tree['score'] = grid_tree.cv_results_['mean_test_score']
pd.pivot_table( cv_result_tree,
index='max_depth',
columns='min_samples_leaf',
values='score',
aggfunc='mean' )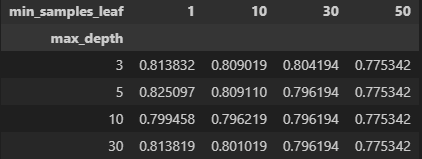
tree = DecisionTreeClassifier( max_depth=5 )
# 훈련
tree.fit(train_x, train_y)
# 검증
tree.score(valid_x, valid_y)# feature 영향성 확인
pd.Series( tree.feature_importances_, index=train_x.columns )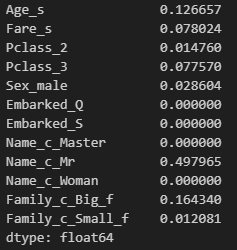
Random Forest
- weak tree * n
- 다양성 추가!
- feature를 랜덤하게 샘플링 함
- 각 나무를 훈련시킬 때 사용하는 데이터를 다르게 샘플링 함
from sklearn.ensemble import RandomForestClassifier
# 배깅 => 여러 모델을 병렬적으로 만들어서 결과를 합침
# 부스트 => 여러 모델을 순차적으로 개선시켜가면서 이어감
# ex) XGBoost : 부스트 모델 중 성능 좋은 모델(사이킷런에 없음, 추가 라이브러리 설치 필요)
# 그리드서치 활용 모델 생성
params = {'max_depth':[3,5,10,20],
'min_samples_leaf':[1,5,10,30]}
grid_rf = GridSearchCV( RandomForestClassifier(random_state=1), params, cv=5 )
grid_rf.fit(train_x, train_y)# 최적의 파라미터 확인
grid_rf.best_params_
# {'max_depth': 10, 'min_samples_leaf': 5} 출력# 그리드서치를 활용하여 생성한 모델이 아래와 같음
# rf = RandomForestClassifier( max_depth=10 )
grid_rf.predict(test_final[feature_names])
# 결과 제출
rf_result = pd.DataFrame( test_final['PassengerId'] )
rf_result['Survived'] = grid_rf.predict( test_final[feature_names] )
rf_result.to_csv('./rf_result.csv', index=False)회귀모델
- 선형 회귀 모델
- 생성
- 훈련
- RMSE, r-squre
- 머신러닝
- target 있나, 없나 => 있다 : 지도학습 / 없다 : 비지도 학습
- target 카테고리나, 연속된 숫자
- 카테고리 : 분류 모델(classification)
- 연속된 숫자 : 회귀 모델
from sklearn.datasets import load_diabetes
temp = load_diabetes()
diabete_df = pd.DataFrame(temp['data'], columns=temp['feature_names'])
diabete_df['target'] = temp['target']# 변수간 상관관계 확인
plt.figure()
sns.pairplot(diabete_df)
plt.show()temp = np.abs( diabete_df.corr() )
plt.figure()
sns.heatmap(temp, annot=True, lw=0.1)
plt.show()
선형 회귀 분석
- 가정 : feature와 target 간에 선형관계를 가진다!
- y = a1 * x1 + a2 * x2 + ... + b
from sklearn.linear_model import LinearRegression
# feature // target
X = diabete_df.iloc[:,:-1]
y = diabete_df['target']
# train // valid
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split(X, y, test_size=0.3, random_state=1)
# 모델 생성
lr = LinearRegression()
# 훈련
lr.fit(train_x, train_y)
# 검증
# 분류 모델 => accuracy ( 0 ~ 1 )
# 회귀 모델 => 실제 정답과 예측값 사이의 '오차'
# => R-square (모델이 데이터를 얼마나 잘 설명하는지 통계적 계산, 0 ~ 1)
lr.score(valid_x, valid_y)# 오차를 계산해 보자!
# rmse
from sklearn.metrics import mean_squared_error
mean_squared_error( valid_y, lr.predict(valid_x) ) ** 0.5coef_ : 회귀계수
pd.Series( lr.coef_, index=train_x.columns )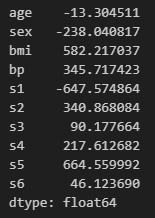
# s1 & s2 중 하나를 제거하고 다시 모델을 만들어 보자
X2 = X.drop('s2', axis=1)
train_x, valid_x, train_y, valid_y = train_test_split(X2, y, test_size=0.3, random_state=1)
# 모델 생성
lr2 = LinearRegression()
# 훈련
lr2.fit(train_x, train_y)
# 예측
lr2.predict(valid_x)
# RMSE
mean_squared_error(valid_y, lr2.predict(valid_x)) ** 0.5# lr2에서 회귀 계수들 살펴보자!
pd.Series( lr2.coef_, index=train_x.columns )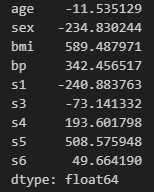
자전거 수요 예측
path = r'파일경로'
train_df = pd.read_csv(path)
path = r'파일경로'
test_df = pd.read_csv(path)# 상관관계 확인
plt.figure(figsize=(5,3))
sns.pairplot(train_df)
plt.show()
결측치 확인
train_df.isna().sum()
test_df.isna().sum()
train_df.describe()Datetime
train_df['datetime2'] = pd.to_datetime(train_df['datetime'])
test_df['datetime2'] = pd.to_datetime(test_df['datetime'])
# 년, 월, 일, 시 분리
train_df['year'] = train_df['datetime2'].dt.year
train_df['month'] = train_df['datetime2'].dt.month
# train_df['day'] = train_df['datetime2'].dt.day
train_df['hour'] = train_df['datetime2'].dt.hour# 년도별 자전거 사용 횟수
plt.figure(figsize=(5,3))
sns.boxplot(train_df, x='year', y='count')
plt.show()# 월별 자전거 사용 횟수
plt.figure(figsize=(15,3))
sns.boxplot(train_df, x='month', y='count', hue='year')
plt.show()# 시간별 자전거 사용 횟수
plt.figure(figsize=(10,3))
sns.boxplot(train_df, x='hour', y='count')
plt.show()# test에도 datetime 별 분리
test_df['year'] = test_df['datetime2'].dt.year
test_df['month'] = test_df['datetime2'].dt.month
test_df['hour'] = test_df['datetime2'].dt.hour# feature engineering
# 스케일링 : 'temp', 'humidity', 'windspeed', 'month', 'hour'
# 인코딩 : 'season', 'holiday', 'workingday', 'weather', 'year'스케일링, 인코딩
# 스케일링
from sklearn.preprocessing import StandardScaler
standard_sc = StandardScaler()
# 어떻게 스케일링 할것인지 훈련
standard_sc.fit( train_df[['temp', 'humidity', 'windspeed', 'month', 'hour']] )
# 실제 훈련한 것을 바탕으로 실행
train_df[['temp_s', 'humidity_s', 'windspeed_s', 'month_s', 'hour_s']] \
= standard_sc.transform( train_df[['temp', 'humidity', 'windspeed', 'month', 'hour']] )
# 인코딩 : 'season', 'holiday', 'workingday', 'weather', 'year'
train_final = pd.get_dummies( train_df, columns=['season', 'weather', 'year'], drop_first=True,
dtype='int' )
test_final = pd.get_dummies( test_df, columns=['season', 'weather', 'year'], drop_first=True,
dtype='int')train_final.columns
feature_names = ['temp_s', 'humidity_s', 'windspeed_s', 'month_s',
'hour_s', 'season_2', 'season_3', 'season_4', 'weather_2', 'weather_3',
'weather_4', 'year_2012', 'holiday', 'workingday']
train_final[feature_names]X = train_final[feature_names]
y = train_final['count']
from sklearn.model_selection import train_test_split
train_x, valid_x, train_y, valid_y = train_test_split( X, y, test_size=0.3, random_state=7 )LinearRegression
# 하이퍼 파라미터
# 모델 생성
# 훈련
# 예측, 검증
from sklearn.linear_model import LinearRegression
# 생성
lr = LinearRegression()
# 훈련
lr.fit(train_x, train_y)
# RMSE, r-square
lr.score(valid_x, valid_y)mean_squared_error(valid_y, lr.predict(valid_x)) ** 0.5RandomForest
# random forest
from sklearn.ensemble import RandomForestRegressor
# 하이퍼파라미터 => grid search
params = {'max_depth':[3,5,10,20],
'min_samples_leaf':[1,10,20,30]}
# 모델 생성
grid_rfr = GridSearchCV(RandomForestRegressor(random_state=1), params, cv=5)
# 훈련
grid_rfr.fit(train_x, train_y)
# 검증 및 예측
grid_rfr.score(valid_x, valid_y)grid_rfr.best_params_
# {'max_depth': 20, 'min_samples_leaf': 1} 출력# RMSE
mean_squared_error(valid_y, gird_rfr.predict(valid_x)) ** 0.5grid_rfr.predict(test_final[feature_names])'Python > 데이터분석' 카테고리의 다른 글
| 데이터분석 DAY2 - pandas, matplotlib, seaborn, 타이타닉 생존율 예측 (0) | 2024.11.03 |
|---|---|
| 데이터 분석 DAY1 - python, pandas, excel to dataframe (1) | 2024.10.21 |
| 10_판다스 데이터 수정 (0) | 2022.07.14 |
| 09_판다스 데이터 정렬 (0) | 2022.07.14 |
| 08_판다스 결측치 확인 (0) | 2022.07.14 |