


import pandas as pd
df = pd.read_excel('score.xlsx', index_col='지원번호')
df['키'] >= 185
filt = (df['키'] >= 185)
df[filt]
df[-filt]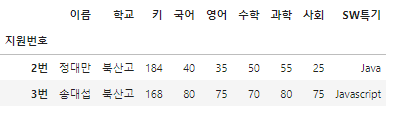
df[df['키'] > 185]
df.loc[df['키'] > 185, '수학']
df.loc[df['키'] >= 185, ['이름', '수학', '과학']]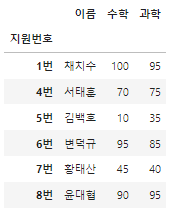
- 그리고 &
df.loc[(df['키'>=185) & (df['학교'] == '북산고')]
- 또는 |
df.loc[(df['키'] < 170) | (df['키'] > 180)]
- str 함수
filt = df['이름'].str.startswith('송') # 송씨 성을 가진 사람
df[filt]
1. contains
filt = df['이름'].str.contains('태') # 이름에 '태'가 들어가는 사람
df[filt]

df[~filt] # 이름에 '태'가 들어가는 사람 제외: 데이터프레임의 조건을 filt라는 변수로 지정 후 반대 선언 시 ~ 사용
2. isin
langs = ['Python', 'Java']
filt = df['SW특기'].isin(langs) # SW특기가 Python 이거나 Java 인 사람
df[filt]
'Python > 데이터분석' 카테고리의 다른 글
| 09_판다스 데이터 정렬 (0) | 2022.07.14 |
|---|---|
| 08_판다스 결측치 확인 (0) | 2022.07.14 |
| 06_판다스_데이터_선택 (0) | 2022.07.10 |
| 05_판다스 데이터 확인 (0) | 2022.07.09 |
| 판다스 DB 연결 (0) | 2022.07.07 |